Senior commercial lawyer. Builder of AI-powered legal tools, developer tooling, and web products. Writing at the edge of law, technology, and systems.
16+
Live Products
6+
Years PQE
2
Jurisdictions
15+
Products Shipped
Selected Work
Legal Apps & Products
Legal, compliance, and regulated-workflow tools built from real practitioner problems.
Legal Tech · Regulatory
LexScope Atlas
Global regulatory applicability triage with version-aware rule evaluation, time-travel checks by effective date, and risk dashboards. No-code admin rule imports.
HTML/JSChart.jsRegTech
EdTech · SQE Prep
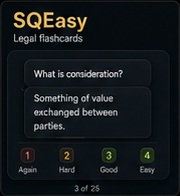
SQEasy
The smartest way to pass SQE1. AI-powered flashcards, SM-2 spaced repetition, 400+ curated MCQs across 14 FLK subjects, mock exams, and real-time analytics.
Next.jsAI-PoweredSM-2
RegTech · EU AI Act
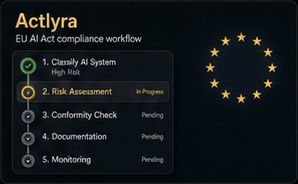
Actlyra
EU AI Act compliance workspace for system inventory, risk classification, evidence tracking, and export-ready governance records.
Senior commercial counsel. Admitted in India, registered in England & Wales.
Background
Senior Commercial Counsel
6+ years post-qualification across financial services, private practice, and in-house roles in India and the UK. LLM from UCL.
Admissions
Bar Council of India
SRA — England & Wales
FRSA — Fellow, Royal Society of Arts
Focus Areas
Commercial Contracts
Technology & IP
Data Protection / GDPR
Cross-border Transactions
Writing
Ideas & Commentary
Essays at the edge of law, AI, and systems thinking.
Legal Tech · AI
How Automated ATS Screening Creates Legal Exposure for Law Firms
When firms use AI to screen applicants without human review, they may be triggering data subject rights under GDPR Article 22 — and most have not thought through what compliance looks like.
12 minJan 2025
Arbitration · India
The Seat-Venue Confusion in Indian Arbitration: A Practical Map
A decade after Bharat Aluminium, Indian courts still produce inconsistent outcomes when parties choose different seats and venues. How to draft around the ambiguity.
18 minOct 2024
Product · Legal Tech
Building LexScope Atlas: What Shipping a Regulatory Triage Tool Taught Me
The hardest part is not the engine. It is deciding which rules to hard-code, which to make configurable, and how much discretion to leave the user. A practitioner-builder's account.
10 minMar 2025
Now
Current Focus
Two parallel tracks, one coherent direction.
01
UK Legal Market Entry
Targeting in-house counsel and legal operations roles in the UK market, with focus on technology, media, and financial services sectors.
02
Legal Tech Products
Actively shipping — LegalMerge, DocBeam, LexScope Atlas, SQEasy, and more. All built from real practitioner pain points, all live on Vercel.
Contact
Let's work together
Product collaboration, legal inquiry, or just want to talk — reach out through the right channel.
Portfolio
Legal Apps
A focused set of legal, compliance, regulated-workflow, and legal-finance products. Broader coding experiments now live separately on Code Counsel.
Global regulatory applicability triage tool with version-aware rule evaluation, time-travel checks by effective date, confidence scoring per dimension, Chart.js risk dashboards, JSON/CSV export, and no-code admin rule imports. The closest thing to a B2B compliance product in the portfolio.
EU AI Act compliance workspace that helps teams move from AI system inventory to risk classification, evidence tracking, conformity tasks, and export-ready governance records.
The smartest way to pass SQE1. AI-powered flashcards with SM-2 spaced repetition science, 400+ curated MCQs modelled on the actual SQE1 format, 14 FLK subject areas, timed mock exams, cohort percentile, real-time analytics, streak tracking, and gamification.
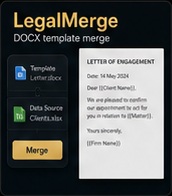
Contract document merging and management tool for legal teams. Combines, compares, and processes legal documents — reducing manual contract assembly time for practitioners handling high document volumes.
England & Wales limitation calculator with statute-grounded rules for 13 claim types. Plain-English prompts guide users through case-specific questions to estimate limitation deadlines, with transparent statute references and defensible reasoning for each date outcome.
Generate production-ready AI prompts in seconds. Customize tone, format, and length for any audience — from customer service to legal drafting to technical documentation. Built for LLM-heavy workflows.
AI-powered content repurposing tool. Takes long-form content — articles, reports, transcripts — and transforms it into multiple formats: social posts, summaries, newsletters, and more.
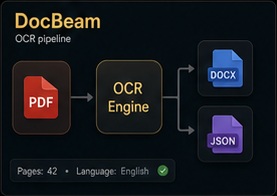
Document transmission and sharing platform for legal and professional use. Secure, fast document delivery with tracking — built for workflows where email attachments fall short.
AI tool that breaks complex projects and goals into atomic, executable sub-tasks. Turns a vague objective into a structured action plan — useful for lawyers managing multi-track matters.
AI-guided thought experiment generator. Explores ideas, hypotheticals, and philosophical scenarios through structured AI dialogue. Built for deep thinking and argument stress-testing.
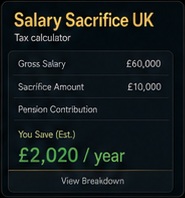
UK-specific salary sacrifice calculator for pension, cycle-to-work, and other benefits. Shows real take-home pay impact with tax and NIC breakdowns. Highest near-term SEO and monetisation opportunity in the portfolio.
Tool for generating and managing GDPR data subject requests — SARs, Article 22 objections, erasure requests, and portability requests — with correct legal wording per UK GDPR and EU GDPR.
The broader app portfolio now has its own home: Apple apps, accessibility tools, developer utilities, AI productivity experiments, finance tools, health apps, browser extensions, and local-first software builds.
Comprehensive personal finance tracking dashboard. Net worth, expense tracking, investment views, and goal monitoring — a PulseBoard for your financial life.
Personal sustainability action planner. Generates tailored green action plans based on lifestyle inputs — transport, diet, home energy, consumption habits — with impact tracking.
Lightweight browser extension for accessibility. Improves contrast, text readability, and keyboard focus across any website. Includes high-contrast themes, font scaling, line-height control, skip-link injection, and per-site overrides — built with accessibility-first principles.
Plug-and-play toolkit for capturing multi-viewport screenshots and recording polished MP4 demo videos of any website. BFS auto-crawl discovery, safety-filtered navigation, and an MCP server for AI assistant integration with Claude and Cursor.
Chrome and Safari extension that suppresses intrusive login popups and restores page usability. Detects, classifies, and hides login walls, scroll locks, and backdrop overlays across LinkedIn, Reddit, Medium, and more — with conservative and aggressive modes.
Senior commercial lawyer. Admitted in India. 6+ years post-qualification experience.
⚠This page is informational only and does not constitute legal advice. No attorney-client relationship is formed by viewing this site. Practice areas reflect experience and professional interests only. Legal services are offered only in jurisdictions where I am duly authorised. Do not submit confidential information through any contact form on this site.
Background
Commercial Lawyer with a Technology Focus
I am a senior commercial lawyer with 6+ years of post-qualification experience spanning financial services, private practice, and in-house roles in India and the United Kingdom. My practice centres on commercial contracts, technology agreements, data protection, and cross-border transactions.
I hold an LLM from University College London.
I am also a Fellow of the Royal Society of Arts (FRSA), and I write and speak on legal technology, AI in legal practice, and international commercial arbitration.
Practice Areas
Areas of Focus
The following reflects experience and professional interests. It is not a statement of services offered in any jurisdiction.
Commercial Contracts
Drafting, reviewing and negotiating MSAs, SaaS agreements, licensing deals, and partnership contracts with domestic and international counterparties.
Technology & IP
Technology agreements, IP licensing, software contracts, and legal frameworks for AI-enabled products and digital services.
Data Protection
GDPR compliance, data processing agreements, Article 22 automated decision-making, and cross-border data transfer mechanisms.
International Transactions
Cross-border commercial arrangements involving UK, EU, US, and Indian counterparties across technology, education, and media sectors.
Arbitration
Published researcher on international commercial arbitration. Focus on Indian arbitration law, seat-venue jurisprudence, and institutional rules.
EdTech & Media
Sector-specific experience in online education, media licensing, and consumer-facing digital platforms at scale.
Selected Writing
Publications & Commentary
Arbitration Law
Seat vs. Venue in Indian Arbitration
Post-BALCO jurisprudence on the seat-venue distinction in Indian arbitral proceedings.
2024Published
AI & Law
GDPR Article 22 and Automated ATS Screening
Data subject rights arising from automated applicant tracking systems used by law firms.
2025Published
Admissions & Credentials
Bar Council of India
Enrolled Advocate · India
Solicitors Regulation Authority
Registered Foreign Lawyer · England & Wales
LLM
University College London
Fellow, RSA
Royal Society of Arts
Professional Inquiries
For legal professional matters, use the dedicated legal inquiry path. Do not include confidential facts in initial contact.
Essays & Commentary
Writing
At the intersection of law, AI, product building, and systems thinking. Where the two lanes meet.
Legal Tech · AI
How Automated ATS Screening Creates Legal Exposure for Law Firms
Jan 2025
12 min
When firms use AI to screen applicants without human review, they may be triggering data subject rights under GDPR Article 22. A practitioner's breakdown of the risk, the right, and what a defensible process requires.
GDPRArticle 22ATS
Arbitration · India
The Seat-Venue Confusion in Indian Arbitration: A Practical Map
Oct 2024
18 min
A decade after Bharat Aluminium, Indian courts still produce inconsistent outcomes on seat-venue. This piece maps the jurisprudence, identifies the drafting traps, and offers clause-level guidance for practitioners negotiating cross-border agreements.
BALCOIndian ArbitrationPublished
Product · Legal Tech
Building LexScope Atlas: What Shipping a Regulatory Triage Tool Taught Me
Mar 2025
10 min
The hardest part was not the engine. It was deciding which rules to hard-code, which to make configurable, and how much discretion to leave the user. A builder-practitioner's account of designing legal tools with real constraints.
LexScopeRegTechProduct Design
AI · Search
Why Legal Search Is a Different Problem Than Enterprise Search
Aug 2024
14 min
Legal search has jurisdictional scope, temporal sensitivity, authority hierarchy, and semantic precision requirements that generic RAG pipelines handle badly. What a purpose-built legal search system actually needs to get right.
RAGLegal AISearch Systems
Data Law · GDPR
Filing Article 22 Requests: What Actually Happens When You Send One
Jun 2024
8 min
After filing GDPR Article 22 requests against firms using automated screening: a realistic account of what responses look like, what compliance gaps they reveal, and what practitioners should know.
GDPRData RightsRecruitment
Product · Indie Building
Shipping 15 Products in a Year While Working as a Lawyer
Feb 2025
9 min
What the stack looks like, where the time goes, why Vercel + Vite + React is the right default for a solo legal builder, and the one decision that would have saved three months of context-switching.
Indie BuildingVercelLegal Tech
When firms deploy AI to screen applicants without meaningful human review, they may be triggering data subject rights under GDPR Article 22 that most firms have not prepared for.
The Problem Nobody Is Talking About
Every major law firm now uses an applicant tracking system. Most of those systems include some form of automated scoring — ranking CVs by keyword match, flagging candidates by education institution, or filtering by GPA thresholds. In many implementations, no human reviews a rejected application before it is binned.
This is efficient. It is also, in a significant number of cases, a GDPR Article 22 compliance failure.
Article 22 of the UK GDPR and EU GDPR gives data subjects the right not to be subject to a decision based solely on automated processing that produces a legal or similarly significant effect. Rejection from a job application almost certainly qualifies as a similarly significant effect. And if no human meaningfully reviews the output before acting on it, the processing is solely automated.
What Article 22 Actually Requires
Where automated decision-making falls within Article 22, the controller must either obtain explicit consent, show it is necessary for a contract, or rely on a Union or Member State law authorisation. In the employment context, most firms rely on the "necessary for a contract" basis — but this is narrower than it looks.
Even where a lawful basis exists, three additional obligations attach:
The data subject must be informed that automated decision-making is taking place.
They must be given meaningful information about the logic involved.
They must have the right to obtain human review, to express their point of view, and to contest the decision.
Most law firm privacy notices say nothing about automated CV screening. The candidate has no idea an algorithm rejected them before a single human read their application. The right to contest? Non-existent in practice.
The "Meaningful Human Involvement" Question
Firms often defend their process by pointing to a recruiter who reviews a shortlist. But there is a problem: if the shortlist itself was generated by automated scoring, and the recruiter only ever sees candidates the algorithm approved, human review of rejected candidates is effectively zero.
The UK ICO guidance is clear that human involvement must be meaningful — not rubber-stamping. A human who sees only approved candidates and clicks confirm does not provide meaningful oversight of the rejection decision.
The operative question is not whether a human touched the process at all. It is whether a human meaningfully reviewed the automated output before a decision adversely affecting the data subject was made.
What a Defensible Process Looks Like
Firms that want to use automated screening lawfully need to address several things simultaneously.
Transparency. Privacy notices must disclose that automated processing occurs, what criteria the system uses, and what the consequences are. Generic boilerplate about "automated processing" does not meet the specificity the law requires.
Human review. If the firm is relying on the Article 22(2)(b) "necessary for a contract" exemption, it must ensure a human genuinely reviews decisions — not just the shortlist, but the rejection decisions too, at least by sample.
Right to contest. There must be a real mechanism for candidates to request human reconsideration. This needs to be communicated proactively, not buried in a privacy notice.
Bias assessment. Automated systems trained on historical hiring data replicate historical biases. Firms should be conducting periodic impact assessments on their screening criteria.
The Article 22 Request as a Tool
One practical consequence of this gap: candidates who suspect they were screened out by an algorithm can and increasingly do file Article 22 requests. The responses are revealing — firms often confirm automated screening took place while claiming no legal obligation attached, without engaging with whether the effect was "similarly significant."
The ICO has enforcement powers here. And as AI-assisted screening becomes more sophisticated, the exposure only grows. Firms that have not reviewed their ATS compliance in the last two years are almost certainly running a process that does not meet the standard.
What to Do Now
For law firms: audit your ATS configuration. Understand exactly what automated decisions it makes, what criteria it applies, and at what point human review enters the process. Update your privacy notice to reflect reality. Build a right-to-contest mechanism that actually works.
For candidates: if you were rejected at the application stage without any apparent human review, you have the right to ask. Request confirmation of whether automated processing was used, what logic was applied, and ask for human reconsideration. You do not need a lawyer to send this request.
This article represents personal views only and does not constitute legal advice.
A decade after Bharat Aluminium, the distinction between seat and venue in Indian arbitration remains one of the most reliably litigated questions in commercial practice. Here is why, and how to draft around it.
Why This Still Matters
The seat of an arbitration determines which court has supervisory jurisdiction over the proceedings and, crucially, which national law governs the arbitration agreement itself. The venue is simply the physical location where hearings take place — a logistical choice with no jurisdictional consequence.
This distinction has been settled law in most major arbitration jurisdictions for decades. In India, it has been contested, reversed, and relitigated to the Supreme Court multiple times. The result is a body of case law that is broadly correct in outcome but chaotic in reasoning, and commercial contracts that routinely create ambiguity where they should create certainty.
BALCO and What It Settled
Bharat Aluminium Co v Kaiser Aluminium Technical Services (2012) was supposed to resolve this. The Supreme Court's five-judge bench held that Part I of the Arbitration and Conciliation Act 1996 — which governs domestic arbitrations and India-seated international ones — does not apply to arbitrations seated outside India. Courts in the seat have supervisory jurisdiction. Foreign awards are enforced under Part II.
What BALCO did not resolve cleanly was how to determine the seat when the contract designates a physical location without using the word "seat." This left open the question that has generated the most subsequent litigation: when a contract says "arbitration in Delhi" or "venue shall be Mumbai," does that designate a seat or merely a physical location?
The Indus Mobile Problem
Indus Mobile Distribution v Datawind Innovations (2017) created a significant divergence. The Supreme Court held that where parties designate a specific seat, that court has exclusive jurisdiction — excluding all other courts, including those at the place where the cause of action arose. This was largely welcome.
But the reasoning in Indus Mobile — and several High Court decisions that followed it — conflated seat designation with venue designation in ways that generated unpredictable outcomes. A clause saying "the arbitration shall be conducted in Bengaluru" was read as a seat clause by some courts and a venue clause by others, depending on whether other connecting factors existed.
The core problem is that Indian courts do not apply a consistent interpretive framework to seat-venue ambiguity. The outcome depends heavily on which High Court is seized of the matter and how much connecting factor analysis the bench is willing to undertake.
BGS SGS SOMA and the Current Position
BGS SGS SOMA JV v NHPC Ltd (2019) brought some clarity. The Supreme Court held that where a contract specifies a seat, that designation confers exclusive jurisdiction on courts at the seat regardless of where the cause of action arose. The "place of arbitration" in Section 20 of the Act can designate a seat. And a clear seat designation in the arbitration clause supersedes any earlier exclusive jurisdiction clause in favour of a different court.
The difficulty is that BGS was addressing a scenario where the clause was relatively clear. Many commercial contracts are not. They specify a physical city for hearings, include a broad governing law clause, and add an exclusive jurisdiction clause pointing to a third court. Untangling this triangle has produced conflicting High Court decisions that BGS did not fully resolve.
Practical Drafting Guidance
The lesson from the case law is that drafting ambiguity costs far more than the time it takes to draft clearly. Clauses that generate this litigation typically share three features:
They use "venue" and "seat" interchangeably, or use neither.
They specify a city for hearings without specifying whether that designation is jurisdictional.
They include a separate exclusive jurisdiction clause pointing to a different court.
A well-drafted arbitration clause for Indian-seated arbitrations should do the following:
Use the word "seat" explicitly. "The seat of the arbitration shall be [city]" is unambiguous. "The arbitration shall be conducted in [city]" is not. Use the first form.
State the supervisory jurisdiction consequence. "The courts of [city] shall have exclusive supervisory jurisdiction over the arbitration." This is redundant once the seat is properly designated, but it eliminates any argument about intent.
Address venue separately if needed. "Hearings may be conducted at such venue as the parties may agree, or as the tribunal may direct." This permits logistical flexibility without creating jurisdictional ambiguity.
Remove conflicting jurisdiction clauses. If the arbitration clause designates Mumbai as the seat, a separate clause giving Delhi courts exclusive jurisdiction over disputes is an invitation to litigation. Delete one or the other.
International Counterparty Considerations
Where one party is non-Indian and the contract has international connecting factors, additional considerations apply. The choice of India as a seat for an international commercial arbitration governed by Part I of the Act should be explicit, and the applicable institutional rules should be specified. Ad hoc arbitrations seated in India with international parties have generated a particularly dense body of conflicting case law on Part I applicability.
For genuinely international contracts, parties routinely prefer seats outside India — Singapore, London, Dubai — specifically to avoid Indian court supervisory jurisdiction. This is a legitimate commercial choice. But if India is the chosen seat, clarity in drafting is not optional.
The Takeaway
The seat-venue distinction in Indian arbitration is settled in theory and contested in practice. The case law is broadly convergent but the path to that convergence has been expensive for the parties who funded the litigation. The cost of a clear clause is two sentences. The cost of an ambiguous one is a multi-year dispute about jurisdiction before the underlying claim is even argued.
This article represents personal views only and does not constitute legal advice.
The hardest decisions in LexScope Atlas were not technical. They were about how much to trust the user, how much to hard-code, and when a confidence score becomes more dangerous than no score at all.
What LexScope Atlas Does
LexScope Atlas is a regulatory applicability triage tool. You input a company profile — jurisdiction, industry, size, product type, entity type, revenue, monthly active users — and a date, and it tells you which regulations in a configurable catalog apply to that profile, with a confidence score and a per-dimension explanation of why.
The motivation was simple: early-stage and mid-market companies routinely mis-scope their regulatory obligations. A UK-based B2B SaaS company with 15 employees and no EU operations does not have the same GDPR obligations as a consumer-facing platform processing 5 million EU data subjects. But when founders search for compliance guidance, they get the same generic answers regardless of their actual profile.
LexScope was an attempt to build something that at least asked the right questions before answering.
The Rule Design Problem
The first real design decision was how to represent regulatory rules in a way that was expressive enough to be useful but simple enough to be maintainable by a non-developer.
The initial instinct was to use a structured JSON schema with nested conditions. This worked, but it produced rules that were opaque — a compliance professional who wanted to add a regulation to the catalog had to understand the schema to do so. That defeated much of the purpose.
The solution was a layered approach: a seed catalog of hard-coded base rules, an auto-import layer for programmatically generated rules, and a local admin import that accepted a simplified JSON or CSV format. The admin layer did most of the translation work internally, converting user-friendly inputs into the engine's native rule format.
The lesson: the interface that matters most is not the one users see. It is the one through which your data enters the system. If that interface is hard to use, your data will be wrong.
Version-Aware Evaluation and Time Travel
Regulations change. GDPR has been amended. The UK GDPR diverged from EU GDPR post-Brexit. Thresholds shift. New rules are added. An applicability tool that gives you the current state of a regulation is only useful if you are always asking about right now.
The time-travel feature — evaluating applicability "as of" a specific date — required the rule structure to support versioning. Each regulation in the catalog can have multiple versions, each with its own effective date and optional repeal date. The engine selects the version active on the requested date before running the evaluation.
This sounds straightforward but produced several edge cases. What happens when a regulation is repealed and replaced by a successor? What about transitional provisions? The current implementation handles the common cases but acknowledges the hard ones by flagging uncertainty rather than suppressing it.
Confidence Scores: Useful or Dangerous?
The confidence score feature was the most contentious design decision. The idea was that a binary "applicable / not applicable" output was too crude — real regulatory analysis always involves uncertainty, and showing that uncertainty is more honest than hiding it.
The risk is that a 73% confidence score on a GDPR applicability determination looks authoritative. A non-lawyer reading it might treat it as a reliable probability. It is not — it is a heuristic based on how many of the assessment dimensions matched, weighted by their relative importance in the rule definition.
The mitigation was threefold. First, a persistent disclaimer that the tool is "scope triage only" and not legal advice. Second, the per-dimension explainability display, which shows exactly which factors contributed to the score so the user can see the reasoning rather than just the number. Third, the export formats — JSON and CSV — which are designed for use by practitioners who will apply judgment to the output, not by end users making decisions based on it alone.
What I Would Do Differently
The catalog seeding process was underestimated. Writing accurate rule definitions for 30+ regulations across multiple jurisdictions took longer than building the engine. Each rule required research into the actual statutory text, threshold values, and exemption conditions. Some of that research is still being corrected in subsequent updates.
A better approach would have been to launch with five well-researched rules and iterate, rather than shipping thirty rules at varying quality levels. The user sees thirty rules and assumes they are all equally reliable. They are not.
The other thing I would do differently is the mobile experience. The tool was designed desktop-first because the expected user was a compliance professional working at a screen. The form is dense. The results panel is wide. On mobile it degrades. That was a deliberate trade-off at the time; in retrospect it was the wrong one.
What It Taught Me About Legal Product Design
The hardest part of building a legal tool is not the legal knowledge or the engineering. It is calibrating how much authority to grant the output. Legal professionals are trained to distrust outputs they cannot fully audit. Non-legal users are inclined to over-trust them.
Every design decision in LexScope — the confidence scores, the dimension breakdowns, the disclaimer text, the export formats — was an attempt to navigate that calibration. The tool should be useful enough to justify using, humble enough to prevent over-reliance, and transparent enough that a qualified professional can check the reasoning. Whether it got that balance right is something I am still learning from the usage data.
This article represents personal views only and does not constitute legal advice.
Generic RAG pipelines fail legal search not because the technology is wrong, but because the problem specification is wrong. Legal search has properties that require different architecture from the ground up.
The Standard RAG Assumption
Most AI-powered search systems — whether enterprise knowledge bases, document repositories, or research tools — share a core architecture: chunk documents, embed them, store in a vector database, retrieve semantically similar chunks on query, and pass them to a language model for synthesis.
This works well for many domains. It works poorly for legal research, and the failures are not random. They cluster around properties of legal text and legal reasoning that are fundamentally different from the documents that enterprise search was designed for.
Property 1: Authority Hierarchy
A statute overrides a regulation. A regulation overrides guidance. A Supreme Court decision binds lower courts. A High Court decision does not bind another High Court but has persuasive weight. A 2024 judgment that interprets a 1996 statute changes how the 1996 statute should be read, retroactively.
Standard vector search has no concept of authority. It retrieves the most semantically similar chunks, which might be a law review article, a government guidance note, and a binding judgment — all with equal weight. A practitioner reading those results would instantly know to weight them differently. The system does not.
A legal search system needs a defined authority hierarchy and the ability to filter or weight results by their position in that hierarchy. This is not a nice-to-have; it is the difference between a tool that helps and one that misleads.
Property 2: Temporal Sensitivity
The law is not a static corpus. Statutes are amended. Regulations are repealed. Case law evolves. A provision that was good law in 2019 may have been overruled by 2023. An enterprise knowledge base can usually tolerate documents being a few months out of date. A legal research tool cannot.
More subtly: the temporal question in legal search is often not "what is the current law" but "what was the law on date X." Contract disputes, historical compliance assessments, and retrospective due diligence all require the ability to query the state of the law at a past point in time. Standard search systems have no concept of temporal provenance in this sense.
Property 3: Jurisdictional Scope
EU GDPR and UK GDPR are not the same regulation. California CCPA and Virginia CDPA are not the same statute. Indian arbitration law and English arbitration law share terminology but reach different outcomes on the same facts.
A legal search system that does not scope results by jurisdiction will surface US case law in response to a UK legal question, or EU guidance in response to a query about Indian law. For users who know the domain, this is noise. For users who do not, it is actively dangerous.
Jurisdictional filtering is not simply a metadata tag on documents. Many legal questions are cross-jurisdictional by nature — a contract dispute involving parties from different countries may require simultaneous analysis of multiple legal systems. The system needs to handle both "retrieve only UK sources" and "retrieve sources from all relevant jurisdictions and label them" queries correctly.
The jurisdictional problem is compounded by the fact that legal text often does not self-identify its jurisdiction clearly. Embedding jurisdiction as document metadata requires editorial work at ingestion time, which generic chunking pipelines do not perform.
Property 4: Semantic Precision
Legal language is precise by design. "Reasonable" and "reasonably practicable" are different standards with different legal consequences. "Shall" and "may" have distinct legal meanings that courts examine closely. "Including" may or may not be exhaustive depending on context and jurisdiction.
Vector embeddings are trained to identify semantic similarity, which collapses many of these distinctions. A search for cases interpreting "reasonable" will surface cases about "reasonably practicable" because the words are semantically close. For many domains, that is the right behaviour. For legal research, it can produce wrong answers.
This does not mean vector search is useless for legal text. It means it needs to be combined with structured querying capabilities — the ability to search by defined legal concepts, statutory references, case citations, and specific terms of art — rather than replacing them.
What a Better Architecture Looks Like
A legal search system built for these properties would combine several things that generic RAG does not.
Structured source metadata. Every document in the corpus should have machine-readable jurisdiction, authority level, effective date, and subject matter classification. This is editorial work, but it is load-bearing.
Authority-weighted retrieval. Retrieved chunks should be ranked not just by semantic similarity but by the authority level of the source. Binding precedent should surface above persuasive authority; primary sources above commentary.
Temporal filtering. The system should support both current-state queries and point-in-time queries, with the ability to filter the corpus to documents effective on a given date.
Citation graph awareness. Legal documents cite each other. A judgment that is overruled by a later case should not be returned as good law. This requires maintaining a citation graph and checking overruling status at query time — something no generic RAG pipeline does.
Why This Has Not Been Built at Scale
The honest answer is that it is expensive. Building the structured metadata layer alone requires significant editorial investment for each jurisdiction covered. Maintaining a citation graph requires ongoing updates as new cases are decided. The resulting system is defensible but narrow — a deep legal research tool for a specific jurisdiction rather than a general search product.
Most legal AI products have made the opposite trade-off: broad coverage, lower precision, and a disclaimer that the output requires expert review. That is a legitimate product decision. But it means the tools currently marketed as "AI legal research" are mostly useful for drafting assistance and initial orientation, not for the precision work that legal research actually requires.
The gap between what these tools claim to do and what they actually do is a reliability problem. Building tools that are honest about their limitations — and architecturally designed to minimise the failure modes specific to legal reasoning — is harder, but it is the right target.
This article represents personal views only and does not constitute legal advice.
After filing GDPR Article 22 requests against several law firms and a recruiter, here is a frank account of what the responses look like and what they reveal about the state of compliance.
Why I Filed the Requests
I applied to a number of UK law firms and a legal recruiter over a six-month period. In several cases, I received rejections within minutes of submitting my application — faster than any human could have reviewed a CV. In one case, I received a rejection before the application deadline had closed.
This is consistent with automated screening. An ATS scores the application against pre-set criteria — keyword matching, institution filters, experience thresholds — and rejects below-threshold applications without human review.
My question was simple: was this Article 22-compliant processing? I decided to find out by exercising the right directly.
What Article 22 Requests Actually Say
An Article 22 request is not a magic phrase. It is a communication asserting that automated decision-making may have occurred in relation to your data, requesting confirmation of whether this is the case, and — where it is — invoking your right to obtain human review, express your point of view, and contest the decision.
The request I sent was brief. It identified the specific application, noted the speed of rejection, asked for confirmation of whether automated processing was used, asked for disclosure of the logic involved, and formally requested human reconsideration of the application if automated processing had occurred.
The Responses — Categorised
Over eight requests filed, I received six substantive responses and two non-responses. The six substantive responses fell into three categories.
Denial without engagement (three responses). These acknowledged receipt and stated that the firm's recruitment process involved human review at all stages and therefore Article 22 did not apply. No detail was provided on what that human review consisted of, when it occurred, or how the decision on my application was made. One response made the specific claim that automated tools were only used to "assist" recruiters, not to make decisions.
Acknowledgment of automated processing, no meaningful remedy (two responses). These acknowledged that the ATS used automated scoring but claimed a recruiter had reviewed the output before the rejection was communicated. No evidence was provided for this. Neither firm offered reconsideration. One provided a brief description of the scoring criteria; the other did not.
Genuine engagement (one response). One firm's Data Protection Officer responded in detail. They confirmed automated scoring had been used, explained the criteria, acknowledged that the rejection had been generated automatically, and offered to have a recruiter review the application manually. They also noted they were reviewing their process in light of the request. This was the response Article 22 was designed to produce.
What the Responses Reveal
The denial responses raise more questions than they answer. If a human reviewed every application before rejection, that review happened within minutes of submission. That is either implausibly fast or it means the "review" consisted of seeing an automated score and clicking confirm — which is not meaningful human oversight under the ICO's guidance.
The acknowledgment-without-remedy responses are the most interesting legally. If a firm acknowledges automated processing occurred, and the processing had a significant effect (rejection from employment), Article 22 requires them to provide a right to contest and obtain human review. Saying "yes, automated processing occurred" while refusing reconsideration is internally inconsistent.
None of the firms that denied automated processing would have any particular incentive to admit it. Article 22 requests do not have discovery powers attached to them. A firm can claim human review occurred and there is no mechanism to verify the claim without regulatory investigation.
The ICO's Role
I submitted a complaint to the ICO in relation to two of the non-engaging responses. The ICO assessed both complaints and declined to investigate, citing resource prioritisation. This is consistent with the ICO's published approach of focusing enforcement resources on systemic issues rather than individual complaints.
The practical implication is that Article 22 rights in the recruitment context are largely self-enforcing. The right exists; the enforcement infrastructure does not match the scale of the violation. This will likely change as automated hiring tools become more sophisticated and more widespread.
What This Means for Practitioners and Applicants
For practitioners advising clients on GDPR compliance: if your client uses ATS scoring in recruitment, conduct an honest audit of whether meaningful human review occurs before rejection decisions are communicated. If a recruiter reviews only shortlisted candidates, that is not meaningful review of rejection decisions. Update the privacy notice. Build a right-to-contest process that actually functions.
For applicants: the right is worth exercising, even if the immediate outcome is limited. It creates a paper trail, puts the firm on notice, and in the best case produces the genuine reconsideration that Article 22 was designed to enable. Filing the request costs nothing.
This article represents personal views only and does not constitute legal advice.
The most common question I get is how. Here is an honest account of the stack, the time, the trade-offs, and the one decision that would have saved three months of wasted context-switching.
The Honest Version of the Numbers
Fifteen products in a year sounds more impressive than it is. Several are simple single-page tools — a calculator, a static dashboard, a basic form handler. Four or five are meaningfully complex applications with real functionality. Two have paying users or are on track to. The rest exist, are deployed, and are at various stages of something between proof-of-concept and neglected MVP.
Shipping fifteen things is not the same as building fifteen good products. But it taught me more about product development than I learned in two years of reading about it, and it produced a portfolio that has opened conversations that nothing else would have.
The Stack
Everything runs on Vercel. The frontend is almost always Vite + React or Next.js, depending on whether I need SSR. Tailwind for styling — not because I think it is the best CSS approach, but because it is fast for solo building. Supabase for anything that needs a database and auth. The Anthropic and Groq APIs for AI features, with Groq as the default for latency-sensitive applications because the free tier is genuinely fast.
For domains: anything that needs to feel like a real product gets a custom domain via Vercel's interface. Everything else lives on .vercel.app.
This stack has one property that matters above all others for solo development: the feedback loop is fast. From idea to deployed URL is typically under two hours if the idea is simple. For more complex projects, I can have something testable in a day. That speed compounds — ideas that would have been abandoned under a slower build process get tested and either validated or killed quickly.
Where the Time Actually Goes
Legal work is not nine-to-five but it is not predictably scheduled either. The reality of building alongside a senior in-house role is that the building happens in carved-out pockets: early mornings, occasional evenings, weekends when nothing urgent is in flight.
Most products got between eight and twenty hours of focused time. The more complex ones — LexScope Atlas, SQEasy — got considerably more, but spread over months rather than concentrated sprints.
The time sink that catches solo builders is not the building. It is the decision-making. Every product requires hundreds of small decisions — what to include, what to cut, how to handle edge cases, whether to fix a bug now or ship and iterate. When you are the only person making those decisions, and you are also handling a complex contract redline at the same time, the context-switching cost is high.
The Decision That Would Have Saved Three Months
The biggest mistake was not deciding earlier what each product was for. Not what it did — what it was for. Who was the user, what was their problem, what would make them come back.
Several products I built were technically interesting and practically purposeless. I built them because the technical challenge appealed or because I had a vague sense there was a use case. None of them went anywhere. The time spent on them was not wasted in the sense that I learned things — but it was wasted in the sense that I could have spent it on the products that actually had legs.
The products that have found traction — LexScope, SQEasy, the GDPR tooling — all share one property: I built them because I had personally experienced the problem they solve. LexScope came from the frustration of spending forty minutes researching which regulations applied to a client's product profile. SQEasy came from my own SQE1 preparation. The GDPR tools came from my Article 22 research.
Build from pain, not from interest. Interest sustains the first weekend. Pain sustains the product through the ugly months when you are fixing bugs nobody has thanked you for fixing.
What AI Changed
The honest answer is: a lot. Claude and Cursor have compressed the implementation time for features that previously would have required either more experience than I had or more time than I could allocate. I can move faster through unfamiliar parts of a stack. I spend less time on boilerplate. I catch more bugs before they ship.
What AI has not changed: product judgment, user understanding, the quality of the ideas, and the grinding work of thinking through edge cases. Those are still the hard parts, and they are still slow.
The risk I am aware of is building things faster than I am learning from them. Speed is only an advantage if you are moving in the right direction. The projects where I slowed down and thought carefully about the product problem before building produced better outcomes than the ones where I started coding immediately.
What I Would Tell Someone Starting This
Pick one thing and make it genuinely good before starting the next one. I did not do this, and it shows in the portfolio — there are several products that are clearly 80% done, where twenty more hours would have transformed them from "functional demo" to "product someone would pay for."
Deploy everything publicly from day one. The discipline of having something live that people might stumble across changes how you build. You make different decisions when the code is public than when it is sitting in a private repository.
And if you are building legal tools: the legal knowledge is your competitive advantage. Most people building in this space are engineers who learned some law. You know the law, and you can learn enough engineering. That asymmetry is worth more than it looks.
This article represents personal views only and does not constitute legal advice.
About
Lawyer who builds. Builder who thinks like a lawyer.
I have spent the last six years working in commercial law across India and the UK — drafting and negotiating complex agreements, advising on data protection, and navigating the legal architecture of technology businesses. In parallel, I have been shipping software.
That combination is not accidental. Legal practice is fundamentally about understanding systems, identifying where they break down, and designing language that constrains risk. Building software requires exactly the same instincts. The products I make — from legal tech platforms to developer tools like Snapcrawl (a Playwright-based screenshot and video capture toolkit with MCP server integration) — are all attempts to close gaps I found frustrating as a practitioner and builder.
I hold an LLM from University College London. I am a Fellow of the Royal Society of Arts.
I write regularly on legal tech, AI, and the design of legal systems. I am interested in civic technology, open data infrastructure, and what it would take to make legal services accessible by default.
This site carries one brand with two distinct lanes. The /legal section is a professional profile, not a marketing page. Content is informational only and does not constitute legal advice.
Credentials
Bar Council of India
Enrolled Advocate
SRA · England & Wales
Registered
FRSA
Fellow, Royal Society of Arts
LLM
University College London
Currently Building
SQEasy
Legal EdTech · sqeasy.vercel.app
LexScope Atlas
RegTech · lexscope-atlas.vercel.app
LegalMerge
Legal Ops · legalmerge.vercel.app
Get in Touch
Contact
Two separate paths. Use the right one — it helps me respond faster and more usefully.